#火焰中的Nodejs
原文链接:http://techblog.netflix.com/2014/11/nodejs-in-flames.html
我们一直在忙于用Node.js构建我们的下一代Netflix.com网络应用。你可以从我们几个月前放在NodeConf.eu的这个演讲中了解更多。今天,我想要分享一些我们在新应用栈的性能调优中学到的一些东西。
我们首先得知了一个可能的问题,当我们注意到我们的Node.js应用中的请求延迟会随时间逐渐增加。并且,应用比起我们的期望消耗了更多的CPU,并且CPU消耗的增长与更高的延迟是密切相关的。我们一边使用循环重启的方式作为一个临时解决方案,一边努力地在我们Linux EC2环境中使用新的性能检测工具与技术想要找到问题的根源。
##火焰上升
我们留意到我们的Node.js应用请求延迟随着时间慢慢增长。特别的,一些方法的延迟会从刚开始时的1ms每小时增加到10ms。并且我们也发现了相关的CPU使用率的增长。
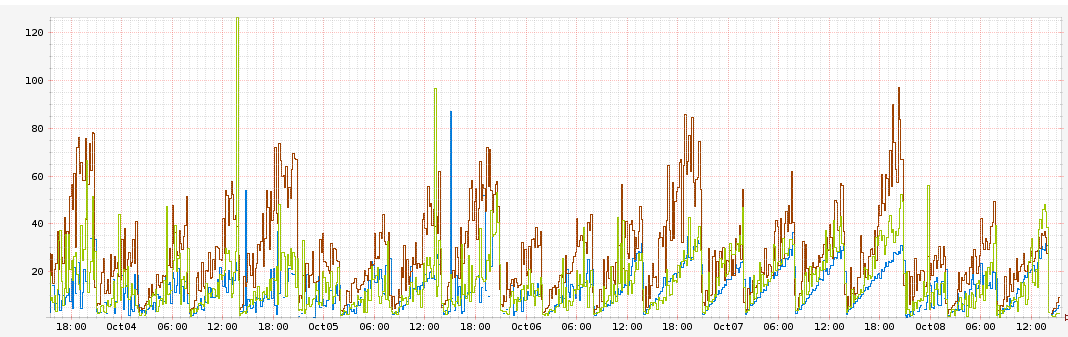
这幅图描绘了对于每个时间区域的请求延迟(以ms为单位)。每种颜色和一个不同的AWS AZ相关。你可以看到延迟稳定地以每小时10ms的速度增长,在实例重启之前能达到60ms的峰值。
##浇灭火焰
最初我们猜想我们自己的request handler里面有一些错误,比如memory leak,因此导致了延迟的增长。我们通过对应用单独的压力测试尝试验证这一猜想,增加了一些系统变量监控:既有我们的request handler单独的延迟,也有整个request的延迟。同时,我们将Node.js的heap size增加到32Gb。
我们发现我们的request handler的延迟在整个性能测试的周期中都是一个常量1ms。我们同时也看到进程的heap size处在约1.2Gb的常量中。但是,整体的request延迟和CPU使用率持续的增长。这宣告了我们自己的handler无罪,并且将问题指向了更深处。
有一些其他的东西消耗了额外的60ms来处理这个request。我们所需要的是一个方法来描述应用的CPU使用率并且将其可视化以便识别我们在哪里部分我们消耗了CPU绝大多数的时间。进入CPU火焰图和Linux Perf Events来进行急救。
对于这些不熟悉火焰图的人,最好的了解方式是阅读Brendan Gregg的精彩的文章,这篇文章解释了它们是什么 - 这里我们给出一个快速的总结(从文章中直接提取)。
- 每一个方块表示一个stack中的函数(一个”stack框架”)
- y轴显示的是stack深度(stack中的框架数量)。最上层的方块显示了当前在CPU的函数。其下面的所有都是它的祖先,紧贴着它下面的是它的父函数,就像我们之前看到的stack trace一样。
- x轴显示的是样例群体。它并不是像绝大多数图片那样从左到右的显示时间流逝。它们的左右顺序不表示任何含义(仅仅是按照字母表顺序排列)。
- 如果有多个CPU并行执行和采样的话,样本数量可能超过所耗时间。
- 颜色并不明显,它们是随机选择成为暖色调。它被成为“火焰图”是因为它显示了现在CPU什么更”hot”。并且它是可交互的,鼠标放置于SVG之上可以看到细节。
之前的Node.js火焰图只被用在使用了DTrace的系统上,使用Dave Pacheco的Node.js jstack()支持。然而,最近Google v8组添加了v8的perf_events支持,它包含Linux上类似的Javascript symbol。Brendan写了关于如何使用这个新支持特性的指南,在Node.js版本0.11.13中到来。在Linux中创建Node.js火焰图。
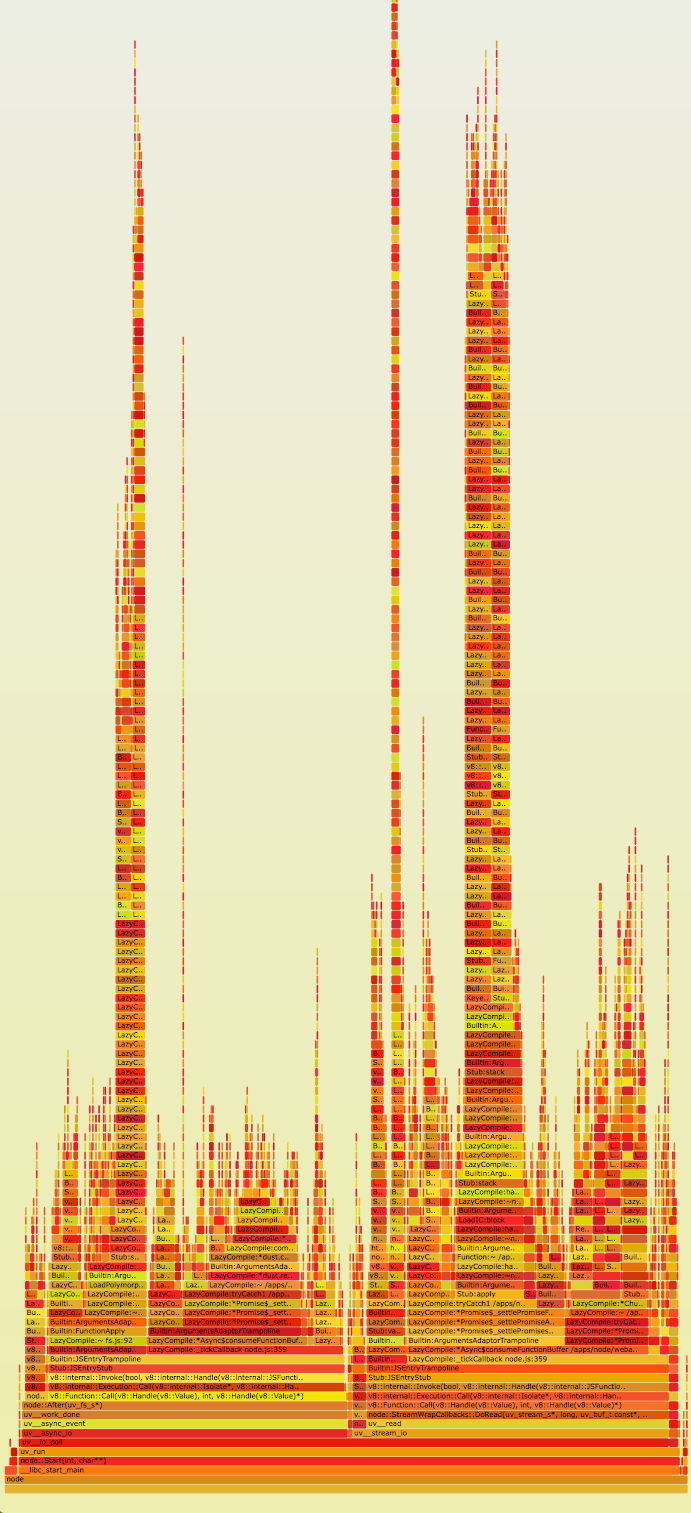
这里是火焰图的原始SVG。我们立刻就注意到在我们的应用中有一些非常高的stack(y轴),我们也能看到我们耗费了非常多的时间在这些stack上(x轴)。更进一步的研究发现,看起来这些stack框全是对Express.js的router handle以及router handle.next函数的引用。Express.js的源代码中我们看到了一些有趣的“花边新闻”。
- 所有endpoint的Route handler都储存在一个全局的数组中
- Express.js通过递归的方式进行遍历并调用这些handler直到它发现正确的路由handler
对于这种应用场景,一个全局数组并不是一个理想的数据结构。我们不清楚为什么Express.js不选择使用一个常量时间的数据结构例如map来保存它的handler。每个请求都需要在路由数组中进行昂贵的O(n)查找以便发现它的route handler。更为复杂的是,数组是通过递归进行遍历的。这也就解释了为什么我们会在火焰图中看到如此高的stack。有趣的是,Express。js甚至允许你对一个路由设置很多相同的route handler。你可能不经意地将将请求链设置成这样:
1 | [a, b, c, c, c, c, d, e, f, g, h] |
对于路由c的请求会在第一次发现c handler时停止(数组的位置2)。但是对于路由d 的请求会在位置6处停止,在轮询a,b以及非常多的c之间无用地耗费了时间。我们通过执行下面的纯express应用来验证它。
1 | var express = require('express'); |
执行该Express.js应用来返回这些route handler。
1 | stack [ { keys: [], regexp: /^\/?(?=/|$)/i, handle: [Function: query] }, |
注意到这里对/foo有两个完全一样的route handler。如果Express.js在对于一个路由有多余一个route handler时可以抛出一个异常就好了。
到现在为止,我们主要的猜想变成了handler数组随着时间在增长,由于每个handler都被调用,因此导致了延迟的增长。极有可能我们在代码中的某处泄露了handler,可能是由于重复handler问题导致的。
1 | [... |
有些东西在以10次每小时的速度添加同样的Express.js静态route handler中。更进一步的基准测试显示了仅仅是遍历每一个handler耗费约1ms的CPU时间。这和我们所见的延迟问题是相关联的,我们看到的响应时间的增加是每小时10ms。
最终结果是:它是由我们代码中的一个周期性函数(10次/小时)导致的。其主要的目的是为了从一个外部源刷新我们的route handler。它是通过从数组中删除旧的handler并添加新的handler来实现的。不幸地是,它在每次执行时也在不经意间增加了一个同样路径的静态route handler。由于Express.js允许对同一路径含有多个route handler,这些重复的handler被全部添加进了数组中。更糟糕的是,它们是被添加到了其他API handler的前面,这表示在任何我们server的请求被执行之前,它们全部都会被调用到。
这完全解释了为什么我们的清秋延迟是以每小时10ms的速度增长的。事实上,当我们修复代码使之停止添加重复route handler之后,我们的延迟以及CPU使用率的增长都消失了。
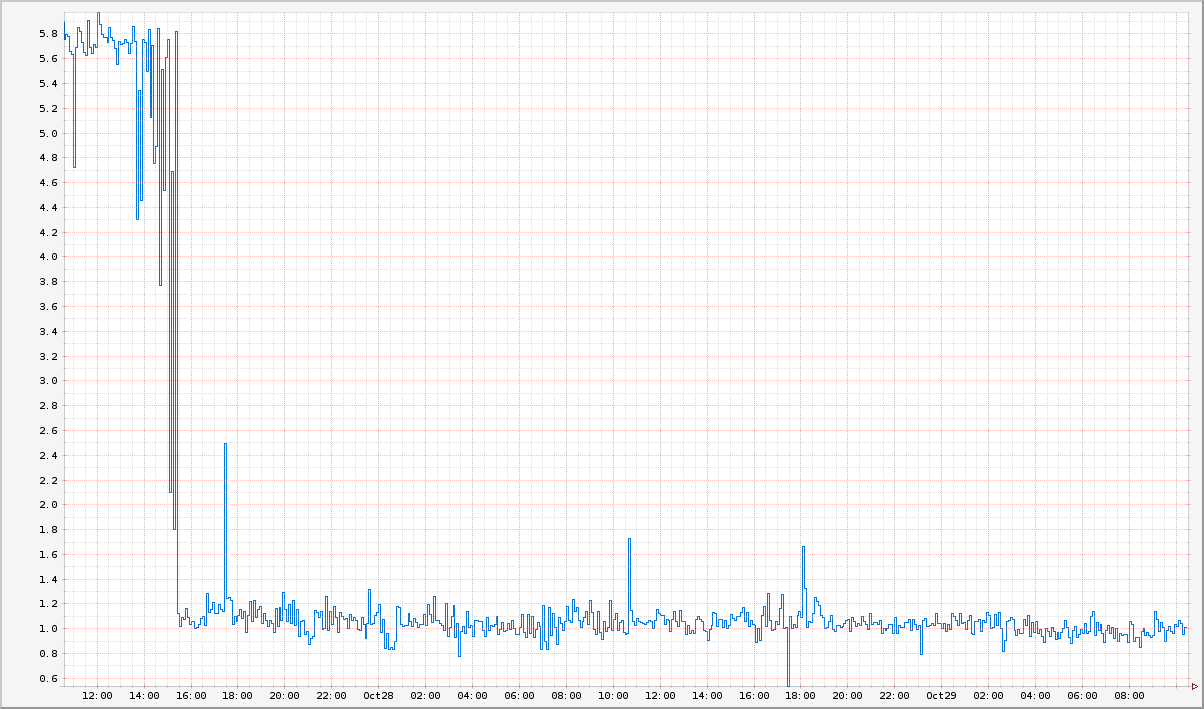
现在,在我们部署了修复代码之后,我们的延迟降低到了1ms并且能够一直保持了。
当烟雾散去
我们从这个悲惨的经验中学到了什么呢?首先,在我们将依赖对象放入生产环境之前,我们必须完全的了解它。我们对Express.js的API进行了错误的假设而没有深度到代码基础中。结果,我们错误的使用了Express.js的API就是我们最终性能问题的根源。
第二,在处理性能问题时,可观察性是至关重要的。火焰图使我们能够洞察到我们的应用程序在哪部分花费了最多的时间在CPU上。难以想象在没有能够对Node.js的stack进行采样以及用火焰图可视化他们的条件下我们该如何解决这个问题。
为了进一步提高可观察性,我们迁移到了Restify,它给了我们更多的同茶行,可见性以及对我们应用程序的操作性。这已经超出了本文的范围,因此请期待我们之后关于如何在Netlix中利用Node.js文章。
本文原作者: Yunong Xiao @yunongx
脚注:
1 特别的,注意在这个代码片段中,next()被递归地调用来遍历名为stack的全局route handler数组。
2 Restify提供了非常多的机制以获取你的应用的可见性。从DTrace支持,到与node-bunyan日志框架集成。