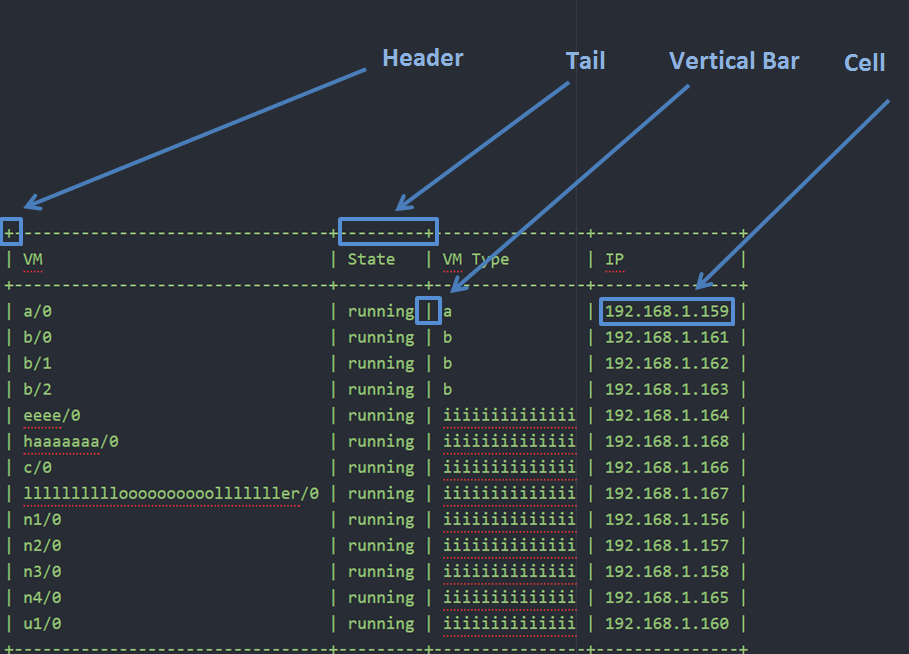
\s+ /* skip whitespace */ <<EOF>> return 'EOF' /* End of file*/ "+" return 'HEAD' /* Header of the separate line */ ("-")+"+" return 'TAIL' /* Tail of the separate line */ [^+|-]*[^\s+|-] return 'CELL' /* Content in the cell, this is what we want */ "|" return '|' /* Vertical bar of the cell */
Today I was solving the problem of “calculate Fibonacci sequence” in Haskell.
The normal fibonacci function is implemented as:
1 2 3 4
fib :: Int -> Int fib0 = 0 fib1 = 1 fib n = fib (n - 1) + fib (n - 2)
However, this implement runs very slow.
There is one possible way to optimize the code as follow:
1 2 3 4
fib :: Int -> Int fib n = aux n (0, 1) where aux n (a, b) | n == 0 = a | otherwise = aux (n - 1) (b, a + b)
This version is a lot faster than the original version. Why?
The trick is tail recursion.
In previous code, when executing fib n = fib (n - 1) + fib (n - 2), there is context switch by pushing current context into call stack in order to resume after fib (n - 1) and fib (n - 2) are calculated.
However, by using tail recursion, because our function aux n (a, b) directly return the result from aux (n - 1) (b, a + b), program can re-use current stack space without change.
// Note: omitting fictional `multBy20(..)` and // `addTo2(..)` asynchronous-math functions, for brevity
function *foo(token) { // grab message off the top of the channel var value = token.messages.pop(); // 2
// put another message onto the channel // `multBy20(..)` is a promise-generating function // that multiplies a value by `20` after some delay token.messages.push( yield multBy20( value ) );
// transfer control yield token;
// a final message from the CSP run yield"meaning of life: " + token.messages[0]; }
function *bar(token) { // grab message off the top of the channel var value = token.messages.pop(); // 40
// put another message onto the channel // `addTo2(..)` is a promise-generating function // that adds value to `2` after some delay token.messages.push( yield addTo2( value ) );
functionstate(val,handler) { // make a coroutine handler (wrapper) for this state returnfunction*(token) { // state transition handler functiontransition(to) { token.messages[0] = to; }
// default initial state (if none set yet) if (token.messages.length < 1) { token.messages[0] = val; }
// keep going until final state (false) is reached while (token.messages[0] !== false) { // current state matches this handler? if (token.messages[0] === val) { // delegate to state handler yield *handler( transition ); }
// transfer control to another state handler? if (token.messages[0] !== false) { yield token; } } }; }
// counter (for demo purposes only) var counter = 0;
ASQ( /* optional: initial state value */ )
// run our state machine, transitions: 1 -> 4 -> 3 -> 2 .runner(
// state `1` handler state( 1, function*(transition){ console.log( "in state 1" ); yield ASQ.after( 1000 ); // pause state for 1s yield transition( 4 ); // goto state `4` } ),
// state `2` handler state( 2, function*(transition){ console.log( "in state 2" ); yield ASQ.after( 1000 ); // pause state for 1s
// for demo purposes only, keep going in a // state loop? if (++counter < 2) { yield transition( 1 ); // goto state `1` } // all done! else { yield"That's all folks!"; yield transition( false ); // goto terminal state } } ),
// state `3` handler state( 3, function*(transition){ console.log( "in state 3" ); yield ASQ.after( 1000 ); // pause state for 1s yield transition( 2 ); // goto state `2` } ),
// state `4` handler state( 4, function*(transition){ console.log( "in state 4" ); yield ASQ.after( 1000 ); // pause state for 1s yield transition( 3 ); // goto state `3` } )
)
// state machine complete, so move on .val(function(msg){ console.log( msg ); });
functionrequest(url) { // this is where we're hiding the asynchronicity, // away from the main code of our generator // `it.next(..)` is the generator's iterator-resume // call makeAjaxCall( url, function(response){ it.next( response ); } ); // Note: nothing returned here! }
function *main() { var result1 = yield request( "http://some.url.1" ); var data = JSON.parse( result1 );
var result2 = yield request( "http://some.url.2?id=" + data.id ); var resp = JSON.parse( result2 ); console.log( "The value you asked for: " + resp.value ); }
// run (async) a generator to completion // Note: simplified approach: no error handling here functionrunGenerator(g) { var it = g(), ret;
// asynchronously iterate over generator (functioniterate(val){ ret = it.next( val );
if (!ret.done) { // poor man's "is it a promise?" test if ("then"in ret.value) { // wait on the promise ret.value.then( iterate ); } // immediate value: just send right back in else { // avoid synchronous recursion setTimeout( function(){ iterate( ret.value ); }, 0 ); } } })(); }
// assume: `makeAjaxCall(..)` now expects an "error-first style" callback (omitted for brevity) // assume: `runGenerator(..)` now also handles error handling (omitted for brevity)
functionrequest(url) { returnnewPromise( function(resolve,reject){ // pass an error-first style callback makeAjaxCall( url, function(err,text){ if (err) reject( err ); else resolve( text ); } ); } ); }
runGenerator( function *main(){ try { var result1 = yield request( "http://some.url.1" ); } catch (err) { console.log( "Error: " + err ); return; } var data = JSON.parse( result1 );
try { var result2 = yield request( "http://some.url.2?id=" + data.id ); } catch (err) { console.log( "Error: " + err ); return; } var resp = JSON.parse( result2 ); console.log( "The value you asked for: " + resp.value ); } );
functionrequest(url) { returnnewPromise( function(resolve,reject){ makeAjaxCall( url, resolve ); } ) // do some post-processing on the returned text .then( function(text){ // did we just get a (redirect) URL back? if (/^https?:\/\/.+/.test( text )) { // make another sub-request to the new URL return request( text ); } // otherwise, assume text is what we expected to get back else { return text; } } ); }
runGenerator( function *main(){ var search_terms = yieldPromise.all( [ request( "http://some.url.1" ), request( "http://some.url.2" ), request( "http://some.url.3" ) ] );
var search_results = yield request( "http://some.url.4?search=" + search_terms.join( "+" ) ); var resp = JSON.parse( search_results );
// first call `getSomeValues()` which produces a sequence/promise, // then chain off that sequence for more async steps getSomeValues()
// now use a generator to process the retrieved values .runner( function*(token){ // token.messages will be prefilled with any messages // from the previous step var value1 = token.messages[0]; var value2 = token.messages[1]; var value3 = token.messages[2];
// make all 3 Ajax requests in parallel, wait for // all of them to finish (in whatever order) // Note: `ASQ().all(..)` is like `Promise.all(..)` var msgs = yield ASQ().all( request( "http://some.url.1?v=" + value1 ), request( "http://some.url.2?v=" + value2 ), request( "http://some.url.3?v=" + value3 ) );
// send this message onto the next step yield (msgs[0] + msgs[1] + msgs[2]); } )
// now, send the final result of previous generator // off to another request .seq( function(msg){ return request( "http://some.url.4?msg=" + msg ); } )
// now we're finally all done! .val( function(result){ console.log( result ); // success, all done! } )
// or, we had some error! .or( function(err) { console.log( "Error: " + err ); } );
function *foo() { var z = yield3; var w = yield4; console.log( "z: " + z + ", w: " + w ); }
function *bar() { var x = yield1; var y = yield2; yield *foo(); // `yield*` delegates iteration control to `foo()` var v = yield5; console.log( "x: " + x + ", y: " + y + ", v: " + v ); }